内容
トップ
エッジコンピューティング
人気のエッジコンピューティング関連コンテンツ
エッジAIと機械学習
機械学習のトレーニング手法
組み込み機械学習(ML)
人気のエッジAI関連コンテンツ
MLソフトウェア(TensorFlowとLiteRTを含む)
Tensorflow
LiteRT
PyTorchとExecuTorch
人気のMLソフトウェア関連コンテンツ
エッジAIとMLハードウェア
要件
NPU
TPU
エントリーレベルの製品
ミドルレベルの製品
アドバンストレベルの製品
エキスパートレベルの製品
その他の製品
人気のエッジAIハードウェア関連コンテンツ
Edge Impulse
人気のEdge Impulse関連コンテンツ
人気のEdge Impulseデバイス
AIによるセンシング
MLを搭載したビジョンセンサ
人気のAIビジョンセンサ
人気のAIビジョンセンサ関連コンテンツ
機械学習を使用したモーションセンサ
人気のAIモーションセンサ
人気のモーションセンサ関連コンテンツ
機械学習を使用した環境センサ
人気の環境AIセンサ
エッジAI
エッジコンピューティングとは、その名の通り、データの発生源に近い場所で処理を行うコンピューティング技術です。これに対し、クラウドコンピューティングはデータセンターといった遠隔地で処理を行います。スマートホームアシスタント(AlexaやSiriなど)には、エッジAIが搭載されてます。「アレクサ」と声をかけると、エッジAIがそのフレーズを認識し、スマートホームアシスタントを起動します。
エッジAIと機械学習は、システムやデバイスのデータ処理方法を根本から変えています。リモートサーバに頼らず、データ発生源でのリアルタイムな意思決定を可能にしました。技術が急速に進化する中、技術者にとってこれらの概念を理解し応用することは、さまざまな産業分野においてリアルタイムで意思決定を行うインテリジェントな自律型システムを開発する上で極めて重要になっています。このマガジンでは、エッジAIと機械学習が活用されているハードウェア、ソフトウェア、そしていくつかの応用事例を取り上げ、それがどのような問題を解決できるのかを紹介しています。

エッジコンピューティング
コンピューティングサービスに対するニーズが日々高まる中、大規模な集中型データセンターからの移行は意外に思われるかもしれません。しかし、データの発生源のすぐ近くで処理することで、プライバシーの懸念を低くすることができます。以前は周辺機器やエンドデバイスの領域であったネットワークエッジに、今や高度な処理能力が備わっています。
多くのリアルタイム処理が、エッジコンピューティングの必要性を高めています。こうしたアプリケーションは、すでにあなたの身の周りで起こっているかもしれません。
- スマートホームアシスタント(Alexa、Google、Siriなど)は、「ウェイクワード」検出をエッジコンピューティングの一形態として活用しています。この場合、デバイスが迅速に応答し、ユーザーのプライバシーを保護する必要があるため、エッジコンピューティングが必要です。
- 先進運転支援システム(ADAS)は、車線を逸脱した場合にドライバーに通知するような機能に重点を置いており、クラウドへの往復処理を待ったり、ネットワーク応答の遅延リスクを負ったりすることはできません。
- 血糖値モニタなどの患者モニタリング機器は、患者の近くで動作します。患者のスマートフォン(またはローカルデバイス)にのみデータを送信することが可能であり、これにより保護された健康データをインターネット上に公開するリスクを減らすことができます。
- 予知保全モデルは、産業用モータの振動量に対して異常検知を行い、モータが焼損するタイミングを検出します。異常が検出された場合にアラートがトリガされ(その後クラウドに送信されます)、それ以外の時間はソフトウェアがエッジでデータを分析します(これによりネットワークの混雑が軽減されます)。
エッジコンピューティングとクラウドコンピューティングの違いは何ですか? 回答を見る
クラウドコンピューティングは、データセンター(通常、データが生成される場所から遠く離れた場所で処理されます)で処理される一連のサービスを指します。クラウドコンピューティングにおける演算負荷(ワークロード)は、中央処理装置(CPU)またはグラフィック処理装置(GPU)を実行するサーバー上で処理されます。
エッジコンピューティングは、データの生成が行われる近くで処理を行うサービスを指します。エッジコンピューティングの演算負荷は、マイクロコントローラやシングルボードコンピュータ(SBC)で処理されることが一般的です。
人気のエッジコンピューティング関連コンテンツ

エッジコンピューティングとAIが、テクノロジをどのように変えているのかを理解する
今日の相互に接続された世界において、データが前例のない速さで生成されており、これまでのクラウドコンピューティングはリアルタイムアプリケーションの需要に応える上での課題に直面しています。
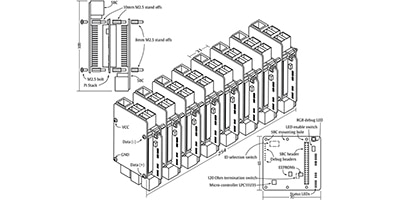
シングルボードコンピュータを使用したIIoTエッジコンピューティングプラットフォームの製作
シングルボードコンピュータ(SBC)を使うとエッジで強力な処理性能を発揮させることができますが、設計者は最善のソリューションを選択して適用する方法を知っておく必要があります。
EfinixのQuantum対応FPGAの活用による、低電力かつ高性能のエッジコンピューティングの実装
EfinixのQuantum対応FPGAを利用することで、AI、ML、画像処理のエッジコンピューティング実装において消費電力、性能、面積の優位性を獲得できます。

IoT技術の設計者がAIとエッジコンピューティングに惑わされない方法
クラウドは、アップロードとダウンロードの帯域幅によって生じる高いレイテンシに悩まされています。これを解決するには、エッジコンピューティングでクラウド通信を最小限に抑えます。

使い慣れたツールでFPGAにエッジAIをデプロイする方法
Altera Agilex 5およびAgilex 3 FPGAが搭載するAI Tensorブロックが、エッジAIの課題を解決し、FPGA AIスイートによる開発を加速させる仕組みについて説明します。
エッジAIと機械学習
人工知能(AI)と機械学習(ML)は、最も広い定義では、直接的かつ明示的な指示がなくてもタスクのパフォーマンスを向上させるコンピュータアルゴリズムや統計モデルを使用することを意味します。開発者がすべての動作を定義する必要がないというこの性質は、あらかじめ定義された従来のプログラミング手法からの変化であり、自律的な改善と適応が可能になります。この特長は、インターネットコンテンツの推薦や音声認識から、医療科学や自律走行車両に至るまで、ほぼすべての分野で新たな用途を見出しています。
今日では、日常生活におけるシステムがますますMLとの何らかのインタラクションを持つようになる中、この世界を理解することは、エンジニアや開発者がユーザーインタラクションの未来を理解する上で極めて重要となります。
人工知能(AI)は幅広い分野であり、特に機械学習(ML)は、エッジにおいて最も将来性がある分野です。機械学習は、統計的アルゴリズムに基づいてパターンマッチングを行うプロセスです。
ニューラルネットワークの活用は、機械学習における一般的なトレーニング方法です。以下の図は、このようなモデルのノードと重み付けを示しています。
 出典:
出典:ディープラーニングは、ニューラルネットワーク内に複数の隠れ層を持つ、機械学習の特殊な形態です。
 出典:
出典:機械学習モデルとは何でしょうか? 回答を見る
機械学習モデルとは、トレーニングデータの中で見つかったパターンに基づいて、入力データを認識し、分類するように設定されたソフトウェアプログラムのことです。トレーニングデータを活用することで、MLモデルはデータで見つかったパターンを抽出し、そのパターンを用いて将来の結果を予測し、より精度の高いモデルへと改良することができます。
機械学習のトレーニング手法
正しく機能するMLモデルを得るには、トレーニングが必要です。モデルのトレーニングに使用できる学習方法には、いくつかの種類があります。
- 教師ありトレーニング - ラベルやタグが付けられたサンプルデータに基づいたトレーニングの一種で、出力は既知の値であり、その正確性をチェックできます。これは、作業を進める中でその作業を修正してくれる家庭教師がいるようなものです。この種のトレーニングは一般的に、分類作業やデータ回帰などの用途で使用されます。教師ありトレーニングは非常に有用で高精度ですが、タグ付けされたデータセットに大きく依存しており、新たな入力に対応できない可能性があります。
- 教師なしトレーニング - 定義された出力を持つラベル付き訓練データの代わりに、教師なしトレーニングでは、学習アルゴリズムを使用して、ラベル付けされていないデータセットからデータのクラスタを調査、分析、発見します。一般的には、教師なしトレーニングは、大規模なデータセットを調査し、データポイント間の関係を見つける必要があるアプリケーションで使用されます。
- 半教師ありトレーニング - 教師ありトレーニングと教師なしトレーニングの両方を組み合わせたものです。訓練データセットには、タグ付きデータとラベルなしデータの両方が含まれます。半教師ありトレーニングは他の手法よりも広範囲の入力データを扱えますが、教師ありトレーニングや教師なしトレーニングよりも複雑になる可能性があり、ラベル付けされていないデータの品質が最終モデルの精度に影響を与える可能性があります。
- 人間からのフィードバックに基づく強化学習(RLHF)- 明確に定義可能なアクション、評価や改善が可能なパフォーマンス指標や結果を用いてトレーニングを行います。ルールセットと実行可能なアクションを定義することで、強化トレーニングは、目標条件を達成するためにさまざまな行動方針の評価を継続して反復できます。
組み込み機械学習(ML)
組み込みMLは機械学習のサブセットで、以下の条件のモデルの実行に焦点を当てています。
- 低遅延(レイテンシ):サーバ応答を待ったり、サーバへのネットワーク遅延に対処する必要がありません。
- 低帯域幅:ネットワーク経由で高解像度のデータを返送する必要がありません。
- 低消費電力:ワット(W)単位ではなくミリワット(mW)です。
組込み型MLモデルは、大規模なデータ処理ハードウェア(サーバやパーソナルコンピュータなど)に依存する代わりに、小型で低消費電力のデバイス(マイクロコントローラ、FPGA、DSPなど)に展開することができます。
組み込みMLアプリケーション向けのモデルのトレーニングは、サーバやコンピュータ上で行われる場合があります。このプロセスでは、すべてのデータが入力され、結果として1つのモデルが生成されます。
一度生成された組み込みMLモデルは、組み込みシステム上で実行されます。組み込みMLにおける一般的なアプリケーションには、ウェイクワードの認識と起動、人物や物体の識別、センサからのデータストリームに基づく異常検知などがあります。
エッジAI(または組み込みML)のメリットとは何でしょうか?回答を見る
- 低遅延(レイテンシ):リモートサーバの応答を待ったり、ネットワークの遅延に悩まされる必要がありません。
- 狭いデータ帯域幅:ネットワーク上で大容量の高解像度データを送受信する必要がありません。
- プライバシー:エッジデバイス上で、事前にフィルタリングされたセンサ出力に基づいて判断を行うため、データをインターネット経由で送信する必要がありません。
- 低消費電力:組み込みMLは、消費電力はワット(W)単位ではなくミリワット(mW)単位であるため、バッテリ駆動のモバイルデバイスに最適です。
- 小さなデータフットプリント:組み込みMLは、数十キロバイト(KB)の小さなフラッシュメモリに収まるように設計されています。
- 経済的で低コストなデバイス:組み込みMLは32ビットのMCUでローカルで演算でき、システム全体のコストは50ドル未満になることがよくあります。
人気のエッジAI関連コンテンツ


機械学習を駆使したホームシーン:インテリジェントなホームオートメーションのための青写真
機械学習により、スマートホームデバイスを新しいシームレスな方法で操作できるようにするスマートホームシーンが実現されます。

エッジにおけるセンシングのためのエコシステム
IoTおよびエッジコンピューティング向けに設計されたセンシングシステムアーキテクチャに対するいくつかのアプローチについて、それぞれの長所と短所を比較しながら紹介します。

NanoEdgeAIStudio:STM32開発者向け自動化された機械学習ツール
NanoEdgeAIStudioは、最小限のデータで最適なMLライブラリを作成できる、開発者のための新しい機械学習(ML)技術です。

MLソフトウェア(TensorFlowとLiteRTを含む)
Tensorflow
TensorFlowは、機械学習モデルの構築、トレーニング、および展開するための無料のオープンソースのソフトウェアライブラリです。2011年にGoogleがGoogle Brainプロジェクトのために開発したもので、2015年に第2世代が一般公開され、2019年に最新版TensorFlow 2.0がリリースされました。
TensorFlowは、深層ニューラルネットワークのトレーニングおよび推論において、最も人気があり、広く使われているフレームワークです。多くの開発者はPython APIライブラリを介してTensorFlowを利用していますが、TensorFlowはJava、JavaScript、C++といったプログラミング言語とも互換性があります。サードパーティのパッケージではオプションが増えていて、MATLAB、R、Haskell、Rustなど、ほとんどすべての言語が利用可能になっています。
LiteRT
以前はTensorFlow Liteとして知られていたLiteRTは、小規模処理向けに設計されたTensorFlowのサブセットです。これには、組み込みシステム、モバイルデバイス、エッジコンピューティングデバイスなど、ハードウェアの制約や電力に制限のあるデバイスが対象となります。開発者は、TensorFlowで既存のMLモデルをトレーニング、作成、または修正した後、LiteRTを使用してより小さく効率的なソフトウェアパッケージに変換することで、モバイルデバイス上で実行することができます。
 出典:
出典:しかし、マイクロコントローラプラットフォームに展開された後は、ローカルで実行するには過大な演算パワーと時間が必要なため、通常はデバイス上でMLモデルをさらにトレーニングすることはありません。つまり、モデルは通常、新たなデータソースなしに完全にオフラインでトレーニングされます。この限定的なアプローチは、単一のタスクを実行するアプリケーションに最適です。ただし、広範囲のデータを分類する必要があります。
TensorFlowとLiteRTの違いは何でしょうか? 回答を見る
TensorFlowは、完全な汎用オペレーティングシステム(GPOS)と、より大規模なコンピューティングハードウェアが必要です。
LiteRTは、組み込みシステム、モバイルデバイス、エッジコンピューティングデバイス上でMLモデルを実行するために最適化されています。
Raspberry Pi 4のようなGPOSで動作するシングルボードコンピュータ(SBC)であれば、適切なサイズのSBC上でフルバージョンのTensorFlowを実行できますが、通常、消費電力はMCUやDSPよりもはるかに大きく、10~20ワットに達することにご注意ください。
一般的に、モデルのトレーニングはTensorFlow上で実行されます。軽量な組み込みシステム上でモデルを実行するためには、LiteRT上で動作するように変換されます。
PyTorchとExecuTorch
 出典
出典ローカライズされたハードウェアプラットフォーム上でMLモデルを実行するというニーズの高まりに応えるため、PyTorchはExecuTorchを開発しました。ExecuTorchは、スマートフォンのようなウェアラブルデバイスや組み込みプラットフォーム上でMLモデルを実行するための完全なエンドツーエンドのソフトウェアツールです。ExecuTorchは、モデリングから変換、展開まで、通常のPyTorchと同じツールチェーンとSDKを使用できるほか、幅広いCPU、NPU、DSPプラットフォームとも互換性があります。
ExecuTorchはPyTorch 2.0をベースとして構築されているため、使いやすく、スマートフォンアプリケーション向けのAndroidサポートを含む幅広いデバイスでサポートされています。
PyTorch Edge、ExecuTorch、PyTorch Mobileの違いは何でしょうか? 回答を見る
PyTorch Edgeは、エッジでMLモデルを実行するというコンセプトです。PyTorch Mobileはこれを実現した従来のツールセットであり、ExecuTorchはエッジでPyTorchモデルを実行するための最新のツールセットです。
PyTorch Mobileは、PyTorchをモバイルデバイス(特にiOS、Android、Linuxベース)に移植するための初期の試みでしたが、アプリケーションの起動時に静的なメモリ占有量を必要とするという制約がありました。一方、ExecuTorchには動的メモリを採用しており、必要な時に必要な分だけメモリを割り当てる仕組みになっています。これは、メモリが制約される環境において極めて重要な機能です。
TensorFlowモデルをPyTorch上(またはその逆)で実行できますか? 回答を見る
TensorFlowとPyTorchは似たようなソフトウェア環境ですが、現時点では直接的な相互互換性はありません。各システムが使用するトレーニング方法やモデルファイルの出力形式が異なるため、あるエコシステムから別のエコシステムへモデルを移行させるのは困難です。
ただ幸いなことに、この2つを簡単に変換できる別の選択肢があります。オープンソースのMLソフトウェアシステムであるONNX(Open Neural Network Exchange)は、MLエコシステム間でトレーニングモデルファイルを変換するツールを備えています。
ONNXがMLエコシステムの仲介的な役割を果たすことで、開発者は多くの異なるMLのトレーニング手法に取り組み、さまざまな手法でモデルを最適化することができます。
人気のMLソフトウェア関連コンテンツ

Syntiant TinyMLを使用するためのソフトウェアについて
Syntiant TinyML(Tiny Machine Learning)開発ボードは、低消費電力の音声、音響イベント検出(AED)、センサMLアプリケーションを構築するためのプラットフォームです。




RenesasのReality AI Tool®に関する技術的なQ&A
RenesasのReality AI Tools®により、エンジニアは高度な信号処理に基づくTinyMLやエッジAIモデルを生成し、構築することができます。
エッジAIとMLハードウェア
TensorFlow Lite for Microcontrollersは、マイクロコントローラ規模のアプリケーション向けに設計されたMLソフトウェアプラットフォームです。オペレーティングシステム、CやC++ライブラリ、または動的メモリアプリケーションを必要としないため、TensorFlow Lite for Microcontrollersは小型でありながら、標準的なプログラミングオプションよりもはるかに強力な性能を発揮します。
なぜマイクロコントローラでエッジAIを行うのでしょうか? 回答を見る
マイクロコントローラは、小型で柔軟性があり、低消費電力で低コストな選択肢であり、世界中の何十億ものデバイスに搭載されています。マイクロコントローラは、完全なコンピュータシステムが不要な場合に有利です。マイクロコントローラは、ローカルで意思決定を行ったり、受信データを処理する能力を備えており、MLの分野で特に注目されています。データをローカルで処理することのさらなるメリットは、エンドユーザーのプライバシーを保護できることです。たとえば、ドアベルの動画データをクラウドに送信することなく、誰かが玄関ドアに近づいているかどうかを知りたい場合などが挙げられます。
要件
TensorFlow Lite for microcontrollers(TFLM)は、C++17プログラミング言語で開発されており、動作には32ビットマイクロコントローラプラットフォームが必要です。
TFLMのソフトウェアコアの機能は、わずか16KBのメモリを搭載したARM Cortex Mプラットフォーム上でも実行可能で、広く普及しているEPS32プラットフォームにも移植されています。適切なArduinoプラットフォームでの動作を希望する場合は、TFLMフレームワーク用のArduinoソフトウェアライブラリも用意されています。
TensorFlow Lite for Microcontrollersにはどのような制約があるのでしょうか? 回答を見る
TensorFlow Lite for Microcontrollersは、最小限のハードウェア要件で動作する強力な機械学習プラットフォームですが、次のような制約があり、開発が困難になる場合もあります。
- 対応デバイスが少なく、通常は、高性能な32ビットプラットフォームが必要になります。
- TensorFlow Liteと同様に、マイクロコントローラ上でのトレーニングはサポートされていません。
- TensorFlowの基本操作のごく一部しかサポートされていません。
- メモリ管理には、低レベルのC++アプリケーションプログラミングインターフェース(API)が必要になる場合があります。
その他の組み込みシステム
組み込みLinuxやRaspberry PiプラットフォームのようなSBCなど、より高性能なハードウェアシステムにMLモデルを実装した場合、TensorFlow liteプラットフォームも同様に実行できます。
ハードウェアアクセラレータ
チップレベルでは、機械学習やニューラルネットワークの演算をサポートするために、特定のプロセッサに専用の演算ロジックが追加されています。
NPU
ニューラルプロセッシングユニット(NPU)は、ニューラルネットワークに基づく機械学習や人工知能アプリケーションの処理を高速化するために設計された専用のICです。
ニューラルネットワークは、人間の脳をモデルにした構造となっており、ニューロンと呼ばれる多くの相互接続された層とノードから構成され、情報を処理し伝達します。
TPU
テンソルプロセッシングユニット(TPU)は、2015年にGoogleが開発した専用ICで、ニューラルネットワークベースのシステムの処理を支援するように設計されていますが、NPUとは異なり、ニューロンベースのシステムアーキテクチャではなく、行列乗算や畳み込み演算を高速に処理することで実現しています。
TPUは、低消費電力で数学的な行列演算をするように高度に最適化されているため、TensorFlowやExecuTorchのような、こうした演算を利用するMLモデルのトレーニングに最適です。
第1世代のTPUハードウェアは、その電源供給と冷却要件のため、通常はデータセンターアプリケーションにのみ導入されています。しかし、最新世代のTPUはエッジベースのアプリケーション向けに設計されています。
エッジAIでは、どうしてCPUやGPUがあまり使われていないのでようか? 回答を見る
従来の中央演算処理装置(CPU)は、汎用演算には優れていますが、ニューラルネットワークのあらゆる演算を効率的に処理するようには最適化されていません。画像処理装置(GPU)もまた、機械学習や人工知能アプリケーションにおいて非常に有用ですが、消費電力や必要なハードウェアのオーバーヘッドが大きいため、エッジでの利用は限られています。
エントリーレベルの製品
![]()

Raspberry PiのPicoBoardは、Raspberry Piが社内開発したRP2040マイクロコントローラチップ用の低コストかつ柔軟性に優れた開発ボードです。


ミドルレベルの製品
![]()

STMicroelectronicsのSTM32N6は、800MHzで動作するArm® Cortex®-M55をベースにしています。Cortex-M55は、Arm Heliumテクノロジーを導入した最初のCPUです。

![]()

Raspberry Pi 5は、64ビットのクアッドコア2.4GHz Arm® Cortex®-A76プロセッサを搭載し、Pi 4に比べてCPU性能が2倍から3倍向上しています。
アドバンストレベルの製品
![]()
STM32MP25第2世代アプリケーションプロセッサ - 近日発売

STMicroelectronicsの第2世代STM32マイクロプロセッサは、接続された産業用アプリケーションにおけるセキュアコンピューティングと高度なエッジAIを実現します。
![]()
ニューラルネットワークアクセラレータを備えた超低電力MAX78000 Arm® Cortex®-M4プロセッサ

Analog Devices のMAX78000は、ニューラルネットワークの超低電力での実行、およびIoTのエッジでの動作を可能にするために構築された新しい種類のAIマイクロコントローラです。
![]()
ARM® Cortex™-M7コアを備えた32ビットSTM32 F7シリーズ MCU

STM32 F7 MCUシリーズは、最大200MHzの周波数で動作し、最大1000 CoreMarkを実現するために、6ステージスーパースカラパイプラインおよび浮動小数点ユニット(FPU)を使用します。
エキスパートレベルの製品
![]()

SeeedのNVIDIA®Jetson Nano™開発者キットは、最新の人工知能ワークロードを効率的かつ小さなフォームファクタで実行するパフォーマンスを提供します。
![]()

SeeedのNVIDIA® Jetsonワンストッププラットフォームは、人工知能(AI)、エッジコンピューティング、および様々な産業用組み込みアプリケーションの開発を強化します。
その他の製品
人気のエッジAIハードウェア関連コンテンツ

DFRobotのオープンソースハードウェアは、AIイノベーションへの障壁をどのように低くするのでしょうか?
シリーズ第1回では、DFRobotのシニアエンジニアRockets Xia氏が次のテーマを解説します。AIは人間の知覚をどのように作り変えようとしているのでしょうか?DFRobotのハードウェアは、専門家だけでなく、どのようにAIイノベーションを身近なものにするのでしょうか?

FPGAを使用して、高性能で電力効率の高いエッジAIアプリケーションを素早く構築します。
専用IPとソフトウェアにより、FPGAの経験がない開発者でもFPGAベースのエッジAIを迅速に展開することができます。

Practical Development Board Resources for Edge AI System Development
This video delves into the shift from “centralized intelligence” to “distributed intelligence,” introducing applications of TinyML and local offline AI.

TI Edge AI - ディープラーニングアクセラレータを搭載した AM6xA プロセッサとその効率性
TIのAM6xA(例えば AM68Ax および AM69Ax )エッジAIプロセッサは、ディープラーニング計算用の特別用途向けのアクセラレータを備えたヘテロジニアスアーキテクチャを採用しています。

エッジアプリケーション向けミッドレンジビジョンAIマイクロプロセッサ
効率的で低消費電力のビジョンAIマイクロプロセッサは、ロボティクス、監視システム、スマートホームデバイス用エッジでリアルタイムの推論が可能です。
Edge Impulse
Edge impulseは、クラウドベースの統合開発環境(IDE)であり、ソフトウェア開発者が実世界のデータを収集、インポートしてMLモデルを構築、トレーニング、テストできるようにします。これにより、エッジコンピューティングデバイス上で効果的に実行することが可能になります。
 機械学習ソフトウェアのEdge ImpulseとTensorFlowの違いについてです。Edge Impulseでは、モデル開発のプロセスがユーザーから抽象化されていますが、TensorFlowでの開発は、はるかに複雑なプロセスとなります。
機械学習ソフトウェアのEdge ImpulseとTensorFlowの違いについてです。Edge Impulseでは、モデル開発のプロセスがユーザーから抽象化されていますが、TensorFlowでの開発は、はるかに複雑なプロセスとなります。
Edge Impulseの得意分野
Edge Impulseのフレームワークは、マイクの音声、カメラの画像、振動センサのデータなど、あらゆるデータを処理できます。その他の例としては、以下のようなものがあります。
- 物体認識と画像検出:人物の検出など
- 音声検出:スマートホームアシスタント用の「ウェイクワード」など
- 異常検知:予防保全用
- アクティビティ/パターン認識:プロセス合理化のため
Edge Impulseを使うべき理由は何でしょうか? 回答を見る
Edge Impulseは、MLトレーニングソフトウェア(現時点では主にTensorFlow)で行う必要のある作業の負荷を軽減することができます。Edge Impulseは、データにタグを付けてアップロードしてモデルをトレーニングできるウェブベースのインターフェースを提供します。
Edge impulseは、MLトレーニングソフトウェアをこれまで使用したことのない初心者やML開発者ではないユーザー向けに設計されていますが、TensorFlow pythonフレームワークと互換性があるため、エキスパートレベルのユーザーにも幅広く対応しています。エッジAIモデルを作成する際に必要となるコーディングの障壁の多くを取り除くことで、適切なデータを提供することや適切なモデルをトレーニングすることに集中することができ、コードを実行するためにどのpythonライブラリを含めるべきかということをあまり気にする必要がなくなります。
ほとんどの開発者やユーザーには無料利用枠が用意されていますが、プロジェクト数や各プロジェクトが利用できる処理能力には制限があります。プロフェッショナルの開発者向けには、有料枠が用意されており、Edge impulseに連絡して料金を交渉できます。
人気のEdge Impulse関連コンテンツ


Bluetoothシステムオンチップを利用したスマートビーコンで機械学習の知見をネットワーク接続して活用
スマートBluetoothビーコンは、システムオンチップテクノロジーを搭載し,運用データをリアルタイムで収集、分析し、機械学習(ML)に基づく知見を提供します。



ホームセキュリティ監視のビデオ映像は誰のものか?
シンプルなビデオドアベルや、敷地内に複数のカメラを配置したネットワークシステムは、クラウドストレージに依存しています。ビデオ映像は誰のもので、どうすれば管理できるのでしょうか?
人気のEdge Impulseデバイス
![]()
NordicのThingy:53 IoTプロトタイピングプラットフォーム

Nordic SemiconductorのNordicThingy:53は、統合されたモーション、サウンド、光、および環境センサを活用して、概念実証とプロトタイプの構築を支援します。

Edge Impulseに対応しているボードの一覧は、こちらをご覧ください。Edge Impulse Edge AIハードウェアの概要
AIによるセンシング
機械学習(ML)モデルの実行には組込みシステムが必要ですが、AI対応の電子部品として、今後もさらに多くの製品が発売されるでしょう。これには、MLセンサとしても呼ばれるAI対応センサも含まれます。
機械学習センサができること
ほとんどのセンサにMLモデルを追加しても、アプリケーションの効率が向上するわけではありませんが、MLトレーニングを行うことで、処理が大幅に効率化できるいくつかのセンサがあります。
- フレーム内の物体や人物を追跡するためのMLモデルを開発できるカメラセンサ
- アクティビティプロファイルを検出するためのIMU、加速度センサ、モーションセンサ
MLを搭載したビジョンセンサ
ニューラルネットを使用して計算アルゴリズムを提供することで、カメラセンサの視野内に移動してくる物体や人物を検出し、追跡することが可能になります。
人気のAIビジョンセンサ
![]()

DFRobotのセンサは、オフラインでAIのジェスチャと顔検出を可能にし、3メートル以内で5種類のハンドジェスチャと最大10人の顔を認識し、クラウドを使用せずにプライバシーを守ります。
![]()
STM32ボード用B-CAMS-OMVカメラモジュールバンドル

STMicroelectronicsのB-CAMS-OMVカメラモジュールバンドルは、5Mピクセルのカメラモジュールと拡張コネクタ付きのアダプタボードで構成されています。

人気のAIビジョンセンサ関連コンテンツ

Renesas RZ/V2シリーズ MPUによる視覚認識システム設計の加速化
Renesas RX/V2 MPUを使用することで、設計者はDRP-AIハードウェアアクセラレータを使用した視覚認識システムを大幅に高速化できます。





機械学習を使用したモーションセンサ
機械学習プラットフォームを統合したモーションセンサは、センサと同じパッケージ内でデータをリアルタイムに追跡・処理することができるため、消費電力と処理時間を削減できます。このタイプのセンサのほとんどは、小規模な論理回路ベースの分岐処理を持つか、フィルタやトリガの閾値を事前定義する機能を備えています。つまり、入力値がこのレベルに達した際に、特定のアクションを実行するというものです。その他のモーションセンサには、パッケージ内に完全なDSPユニットを内蔵しており、メインCPUを使用せずに複数のMLアルゴリズムを実行できるため、電力と時間を節約できます。
人気のAIモーションセンサ

![]()
BHI385スマートIMU:高ダイナミックモーションセンシング用組み込みAI

Bosch Sensortecの完全プログラム可能慣性計測ユニットBHI385は、拡張g加速度センサ、統合型AI、および超低消費電力を特長としています。
人気のモーションセンサ関連コンテンツ

開発ボードとモジュールを活用してマルチモーダルセンシングAIを実現
本日、「AIで現在を再定義する」シリーズの第3回は、DFRobotの講師Rockets Xia氏が、AIがどのようにして単一機能の制約を突破し、人間のように「聞く、話す、見る」ことができるようになったのかを解説します。
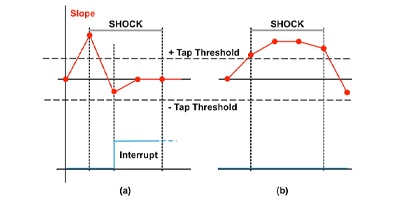
スマートセンサに内蔵される機械学習コアを使用して「常時オン」モーショントラッキングを最適化
機械学習コアを統合したスマートセンサを使用して、複雑な動きのシーケンスを低電力の常時オンによるモーショントラッキングで検出します。

徹底解説:AI環境センシングシステムを効率的に開発するためのセンサおよび開発ボードキット
しかし現在、AIとセンサで構成された「スーパーセンシングシステム」が、こうした目に見えない環境の実態を解き明かし始めています。
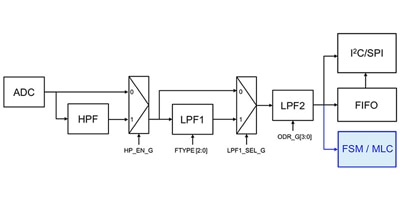
大量の生センサデータは本当に必要ですか?いいえ、より優れた方法があります
スマートセンサを使用してデータセットを削減することにより、生の測定値よりも関心のあるイベントにアプリケーションの焦点を当てることができます。
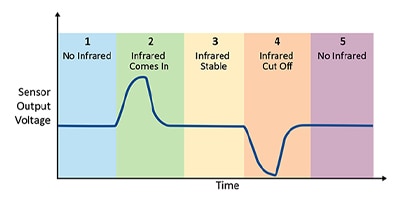
ATtiny1627 Curiosity Nanoを使ったモーション検出の効率化
Microchip ATtiny1627 Curiosity NanoセンサとPIRセンサを使用すれば、モーション検出の手順を素早く学習して使用し始めることができます。
機械学習を使用した環境センサ
機械学習プラットフォームを統合した環境センサは、データをリアルタイムで処理し、ボード上でML処理も行います。このタイプのセンサのほとんどは、環境値の変化を検知します。たとえば、温度の急速な上昇は、冷凍機が停止したことを示している可能性があります。


